
Comparing the Accuracy of 4 Commonly Used Models in Transfer Learning

S
I am a self-taught Python developer who loves to write on Python Programming and quite obsessed with Machine Learning.
Search for a command to run...
I am a self-taught Python developer who loves to write on Python Programming and quite obsessed with Machine Learning.
No comments yet. Be the first to comment.
When you’re building an application, one thing you can’t skip is API testing. Whether it’s a login flow, payment gateway, or a complex e-commerce workflow, ensuring your APIs behave correctly saves you from nasty surprises in production. I had alread...

PyPy is an implementation of Python written in RPython (Reduced Python) language, and it is seen as a replacement for CPython. PyPy claims that it is almost a drop-in replacement for CPython and can beat it on speed and memory usage. It supports libr...

You must have used functions provided by the os module in Python several times in your projects. These could be used to create a file, walk down a directory, get info on the current directory, perform path operations, and more. In this article, we’ll...

FastAPI is a fast and modern web framework known for its support for asynchronous REST API and ease of use. In this article, we’ll see how to stream videos on frontend in FastAPI. StreamingResponse Stream Local Video FastAPI provides a StreamingRespo...
Have you ever come across circular imports in Python? Well, it’s a very common code smell that indicates something’s wrong with the design or structure. Circular Import Example How does circular import occur? This import error usually occurs when two...
There are deep learning models that are pre-trained on millions of image data. These models reduce the effort to train the custom deep learning model from scratch, you need to fine-tune them and they are ready to be trained on your dataset.
Keras provides a high-level API for using pre-trained models. You can easily load these models with their pre-trained weights and adapt them to your specific tasks by adding custom classification layers on top of the pre-trained layers. This allows you to perform transfer learning efficiently.
In this article, you'll see which of the four commonly used pre-trained model (VGG, Inception, Xception, and ResNet) is more accurate with their default settings. You'll train these models on the image dataset and at the end you will able to conclude which model performed the best.
| Model Name | Top-1 Accuracy | Top-5 Accuracy | Parameters |
| VGG16 | 71.3% | 90.1% | 138.4M |
| Xception | 79.0% | 94.5% | 22.9M |
| ResNet50 | 74.9% | 92.1% | 25.6M |
| InceptionV3 | 77.9% | 93.7% | 23.9M |
You can see that the Xception has the highest top-1 and top-5 accuracy among these models and it is trained on 22.9 million data points.
In this section, you'll train the aforementioned models on the cats and dogs image dataset and evaluate the accuracy.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, GlobalAveragePooling2D, Dropout
from tensorflow.keras.applications import Xception, InceptionV3, VGG16, ResNet50
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from sklearn.metrics import accuracy_score
All the modules and classes that will be required throughout this article are imported.
Sequential will be used to lay the architecture of the model.
Dense layer will be used to add the fully connected layer, Flatten will be used for flattening the layer from 2D to 1D, GlobalAveragePooling2D will be used to reduce the dimensions of neural networks, and Dropout will be used to regulate the neurons by randomly shutting the neurons to avoid overfitting.
Pre-trained models (Xception, InceptionV3, VGG16, and ResNet50) are imported from the tensorflow.keras.applications module.
ImageDataGenerator will be used for preprocessing the images.
accuracy_score will be used to determine the accuracy of the models on the test dataset.
# Specifying train, valid and test directory paths
train_path = "D:/SACHIN/Jupyter/Transfer Learning Model Comparison/cats_and_dogs/train"
valid_path = "D:/SACHIN/Jupyter/Transfer Learning Model Comparison/cats_and_dogs/valid"
test_path = "D:/SACHIN/Jupyter/Transfer Learning Model Comparison/cats_and_dogs/test"
The dataset is divided into three directories: train, valid, and test, with two subdirectories within each: cat and dog.
The full path to each of these directories is specified: train_path holds training data, valid_path holds validation data, and test_path holds testing data.
# Preprocessing images
train_batches = ImageDataGenerator(rescale=1.0 / 255.0)
valid_batches = ImageDataGenerator(rescale=1.0 / 255.0)
test_batches = ImageDataGenerator(rescale=1.0 / 255.0)
The ImageDataGenerator is used to preprocess images for training, validation, and testing datasets.
The images will be rescaled to have pixels between 0 and 1. More specifically, resacle=1.0/255.0 means that each input image's pixel value will be divided by 255 to scale down the pixel values.
# Train data generator
train_gen = train_batches.flow_from_directory(
directory=train_path,
target_size=(224, 224),
classes=['cat', 'dog'],
batch_size=10
)
# Valid data generator
valid_gen = valid_batches.flow_from_directory(
directory=valid_path,
target_size=(224, 224),
classes=['cat', 'dog'],
batch_size=10
)
# Test data generator
test_gen = test_batches.flow_from_directory(
directory=test_path,
target_size=(224, 224),
classes=['cat', 'dog'],
batch_size=10,
shuffle=False
)
This step involves creating data generators for training, validation, and testing data.
The first line of code uses the flow_from_directory() method to generate training data with the following parameters:
directory=train_path: Training directory path from where the images will be loaded.
traget_size=(224,224): This resizes the image dimensions into 224x224 pixels.
classes=['cat', 'dog']: Defines the classes for classification.
batch_size=10: The generator will produce batches of 10 images at a time.
Similarly, this process will be repeated for validation and testing data. However, because the shuffle parameter is set to False, testing data will not be shuffled.
Found 1000 images belonging to 2 classes.
Found 200 images belonging to 2 classes.
Found 100 images belonging to 2 classes.
As you can see, 1000 images belong to 2 classes i.e., "cat" and "dog" (500 images for each class) found in the train directory. The valid and test directories found 200 and 100 images respectively.
# Initializing models
model_vgg = VGG16(include_top=False, input_shape=(224, 224, 3)) # include_top=False: To not include first 3 fully connected layers
model_xception = Xception(include_top=False, input_shape=(224, 224, 3)) # include_top=False: To not include fully connected layers at the top
model_inception = InceptionV3(include_top=False, input_shape=(224, 224, 3)) # include_top=False: To not include fully connected layers at the top
model_resnet = ResNet50(include_top=False, input_shape=(224, 224, 3)) # include_top=False: To not include fully connected layers at the top
The pre-trained models are initialized (VGG16(), Xception(), InceptionV3(), and ResNet50()) with the parameters are as follows:
include_top=False: This means that the fully connected layers will not be included at the top of the neural networks.
input_shape=(224, 224, 3): The pre-trained models are initialized with the input shape of the images set to 224x224 with the RGB (3) color channel.
# Freezing the layers so that they cannot be trained again
names = [model_vgg, model_xception, model_inception, model_resnet]
for model in names:
# Iterating all the layers in the pre-trained model
for layer in model.layers:
# Making trainable layers set to False
layer.trainable = False
The above code loops through the list of pre-trained models stored in the names variable, and then the inner loop iterates through the layers of each pre-trained model, freezing them by setting the trainable layer to False (layer.trainable = False).
This step is included because the layers have already been trained and it is pointless to train them further during fine-tuning. That is the entire purpose of employing the transfer learning technique.
# Fine-tuning the pre-trained models
output_classes = len(train_gen.class_indices)
# Custom VGG16 model
custom_vgg_model = Sequential([
model_vgg,
Flatten(),
Dense(256, activation='relu'),
Dropout(0.5),
Dense(output_classes, activation='softmax')
])
# Custom Xception model
custom_xc_model = Sequential([
model_xception,
GlobalAveragePooling2D(),
Dense(output_classes, activation='softmax')
])
# Custom Inception model
custom_inc_model = Sequential([
model_inception,
GlobalAveragePooling2D(),
Dense(output_classes, activation='softmax')
])
# Custom ResNet model
custom_resnet_model = Sequential([
model_resnet,
GlobalAveragePooling2D(),
Dense(output_classes, activation='softmax')
])
The number of classes present in the training dataset is determined using the len(train_gen.class_indices) and stored inside the output_classes variable.
A new Sequential model (custom_vgg_model) is constructed with the pre-trained VGG16 model and custom layers are added to it. The layers are flattened to a 1D vector using the Flatten() layer followed by a fully connected (Dense) layer with 256 neurons and an activation function "ReLu" is added. Then a Dropout layer with a rate of 0.5 (50%) is added regulating the neurons in the neural network and finally, an output layer (Dense) is added with output_classes and activation function "Softmax".
A custom model custom_xc_model is constructed with a pre-trained Xception model (model_xception). A GlobalAveragePooling2D layer is added to reduce the dimensionality of the model and an output layer (Dense) is added with output_classes and activation function "Softmax".
Similarly, custom_inc_model and custom_resnet_model are constructed with pre-trained InceptionV3 (model_inception) and ResNet50 (model_resnet) models respectively.
# Compiling the model
models = [custom_vgg_model, custom_xc_model, custom_inc_model, custom_resnet_model]
for model in models:
model.compile(
optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy']
)
A list called models is defined that contains a collection of fine-tuned models.
A loop is created that iterates through the models in the list, and each model is compiled with an optimizer named "Adam", the loss is computed using 'categorical_crossentropy', and the 'accuracy' is used as metrics to measure the accuracy.
# Training the model
model_names = [(custom_vgg_model, "VGG16"), (custom_xc_model, "Xception"), (custom_inc_model, "InceptionV3"), (custom_resnet_model, "ResNet50")]
for model, model_name in model_names:
print(f">>> Training {model_name} model:")
model.fit(
train_gen,
validation_data=valid_gen,
epochs=10,
verbose=0
)
print(f">>> Evaluating {model_name} on the test set:")
test_pred = model.predict(test_gen)
test_labels = test_gen.classes
test_accuracy = accuracy_score(np.argmax(test_pred, axis=1), test_labels)
print(f">>> Test Accuracy for {model_name}: {test_accuracy * 100:.2f}%:")
A list (model_names) is created in which each item is a pair that consists of a fine-tuned model (e.g. custom_vgg_model) and model name (e.g. "VGG16").
A loop is created that iterates through the fine-tuned model and associated model name from the list model_names. The model.fit() method is called to train each model with the following arguments:
train_gen: Training data generator that will provide batches of training data on which the model is going to be trained.
validation_data=valid_gen: Validation data generator that will be used to check the performance of the model on the validation set without actually training on it.
epochs=10: The model will train for 10 epochs which means the model will train the entire training set 10 times.
verbose=0: This will not show any progression on the screen.
Then the model predicts on the test_gen data using the model.predict() function and store the results inside the test_pred.
Following that, the actual test labels are collected using the test_gen.classes and stored inside the test_labels variable. This will be used to compare against the predicted labels.
In the final step, the accuracy of the models is evaluated using the accuracy_score. The accuracy is determined by comparing the true test labels (test_labels) with predicted test labels (np.argmax(test_pred, axis=1)).
Here, np.argmax(test_pred, axis=1) is used to pick out the max element from the array (test_pred). Using this, you get the array of class labels 0 and 1.
>>> Training VGG16 model:
>>> Evaluating VGG16 on the Test data:
10/10 [==============================] - 19s 2s/step
>>> Test Accuracy for VGG16: 91.00%.
>>> Training Xception model:
>>> Evaluating Xception on the Test data:
10/10 [==============================] - 1s 44ms/step
>>> Test Accuracy for Xception: 100.00%.
>>> Training InceptionV3 model:
>>> Evaluating InceptionV3 on the Test data:
10/10 [==============================] - 2s 55ms/step
>>> Test Accuracy for InceptionV3: 99.00%.
>>> Training ResNet50 model:
>>> Evaluating ResNet50 on the Test data:
10/10 [==============================] - 2s 45ms/step
>>> Test Accuracy for ResNet50: 62.00%.
When you run each model for 10 epochs on the training dataset, the following accuracy on the test data is obtained:
VGG16: 91%
Xception: 100%
InceptionV3: 99%
ResNet50: 62%
As can be seen, the Xception model performed exceptionally well and achieved 100% test accuracy, whereas the ResNet50 model struggled to learn and achieved 62% test accuracy.
You can try out different pre-trained models and datasets. During fine-tuning, you can also experiment with increasing the number of epochs or adding more fully connected models.
Please keep in mind that your results may vary depending on the various factors.
You can determine the learning curve for each model by visualizing the training and validation accuracy for each epoch.
Adjust the above code as shown below:
# Training the model
model_histories = [] # To store train and valid accuracies
model_names = [(custom_vgg_model, "VGG16"), (custom_xc_model, "Xception"), (custom_inc_model, "InceptionV3"), (custom_resnet_model, "ResNet50")]
for model, model_name in model_names:
print(f">>> Training {model_name} model:")
result = model.fit(
train_gen,
validation_data=valid_gen,
epochs=10,
verbose=0
)
model_histories.append((result.history, model_name))
print(f">>> Evaluating {model_name} on the Test data:")
test_pred = model.predict(test_gen)
test_labels = test_gen.classes
test_accuracy = accuracy_score(np.argmax(test_pred, axis=1), test_labels)
print(f">>> Test Accuracy for {model_name}: {test_accuracy * 100:.2f}%.")
# Plot learning curves for each model
plt.figure(figsize=(12, 6))
for i, (history, model_name) in enumerate(model_histories):
plt.subplot(2, 2, i + 1)
plt.plot(history['accuracy'], label='Train Accuracy')
plt.plot(history['val_accuracy'], label='Valid Accuracy')
plt.legend()
plt.title(f'Model Name = {model_name}')
plt.suptitle("Model Performance")
plt.tight_layout()
plt.show()
The above code will produce the following image showing the plots for each model that contains two lines: training accuracy and validation accuracy:
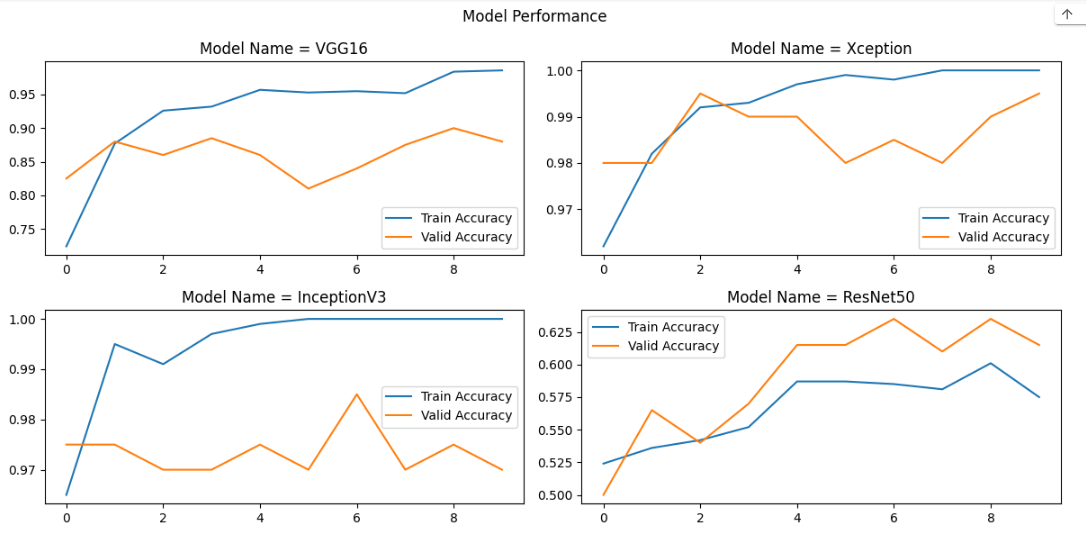
Using the plot above, you can examine the training and validation accuracy of each model. As can be seen, the InceptionV3 model achieved 100% test accuracy around the 5th epoch, while the Xception model achieved 100% test accuracy around the 7th epoch.
In this tutorial, you've seen commonly used (VGG, Xception, Inception, and ResNet) pre-trained models are fine-tuned and then trained on the image dataset to see their performance on the test data.
🏆Other articles you might be interested in if you liked this one
✅How do learning rates impact the performance of the ML and DL models?
✅How to build a custom deep learning model using transfer learning?
✅How to build a Flask image recognition app using a deep learning model?
✅What is StandardScaler() in ML and why it is used?
✅How to perform data augmentation for deep learning using Keras?
✅Upload and display images on the frontend using Flask in Python.
That's all for now
Keep Coding✌✌